

- DNA contains a code which dictates the sequence in which amino acids are to be linked together to make a protein.
- The sequence of bases in a gene is a code for the sequence of amino acids in a protein.
- This relationship of nucleotide bases of a gene and the amino acids is known as the genetic code.
- The genetic code is a set of rules defining how the four-letter code of DNA is translated into the 20-letter code of amino acids, which are the building blocks of proteins.
- It can also be defined as a set of three-letter combinations of nucleotides called codons, each of which corresponds to a specific amino acid or stop signal.
- The smallest unit of 3 nitrogenous bases that codes for one amino acid of polypeptide chain is called a codon or code word.
- The code in a DNA molecule is carried in the sequence of the four bases, adenine (A), guanine (G), thymine (T), and cytosine (C).
- This base sequence is always ‘read’ in the same direction.
- There are 20 amino acids available in the cells which are coded by AUGC letter.
- The genetic information coded in these letters are passed into mRNA and then into proteins.
- The concept of codons was first described by Francis Crick and his colleagues in
- Marshall Nirenberg and Heinrich J. Matthaei were the first to reveal the nature of a codon in 1961.
- Experimental evidence shows that the code is a triplet one and 61 of the 64 codons code for individual amino acids during protein synthesis.
- The remaining three codons are called terminating codons or stop signals.
- These codons (UAA UAG UGA) are used by the cell to signal the ending point of protein synthesis.
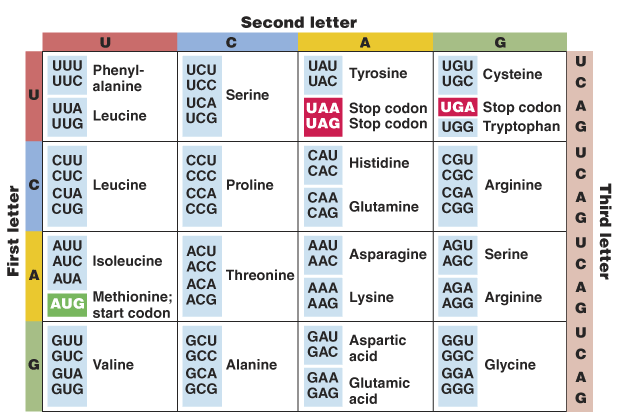
Image source: readbiology
Properties of genetic code
Some of the properties of genetic code have been studied and proved experimentally. They are as follows:
1.The genetic code is triplet
- A genetic code consists of three nitrogenous bases.
- There are 64 possible different codons which code for 20 different amino acids.
- Examples: UAA UGC CCU, etc.
2.The genetic code is commaless
- There is no punctuation (comma) between the adjacent codons.
- It means that if one amino-acid is coded the another amino acid will be automatically coded by the next three letters.
- Examples: UUU CCC ACG GGA, etc.
3.The genetic code is universal
- The same genetic code is used to code the same aminoacid.in all organisms including virus.
- Example: If CAU and CAC codes for histidine in one organism the same triplet is used in another organism to code histidine.
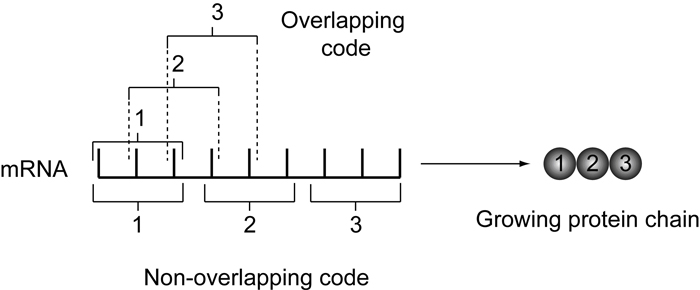
4.The genetic code is non-overlapping
- The same letter is not used for two different codons.
5.The genetic code is degenerate
- It means that more than one code may be used for one amino acid.
- The multiple system of coding is called degenerate system or degenerate code.

6.The genetic code is non-ambiguous
- It means that the particular codon will always code for the same amino acid.
- However, there is some exception like GGA codes for two amino acids glycine and glutamic acid.
7.Initiation codon
- AUG codon is called starting codon as it initiates polypeptide chain formation.
8.Non sense codon
- Certain codons like UAA, UAG and UGA do not code for any amino acid and give an indication for the termination of the polypeptide chain.
- Therefore, they are called termination or non-sense codons.
9.The genetic code has polarity
- The code always read in a fixed direction, i.e. in the 5’→ 3’ direction.
References:
i) https://www.nature.com/scitable/definition/genetic-code-13/
ii) https://journals.asm.org/doi/10.1128/JB.00091-19